VPS

Here's a weekend thousands of developers have now had. Friday afternoon: you walk your office with a $500 360 camera. Twenty minutes, one pass. By evening a pipeline has turned the footage into a Gaussian splat, and you're flying through a photoreal copy of your own building in a browser tab at 60 fps. It works. It's beautiful. You send the link to everyone.
Monday morning: you're standing in the real office, phone in hand, and you ask the obvious next question. Can my phone know where it is inside this thing? Can I pin a note to that wall and find it there tomorrow?
Nothing. The splat can't answer. Its origin sits wherever you happened to press record. Its scale is whatever the solver guessed. Your photoreal twin floats in a private void, gorgeous and unreachable.
That gap is what this post is about.
My goal here is to explain why the splat boom has an indexing problem, how localization against a splat actually works, and what it takes to turn a scene you can look at into a space you can use. It's written primarily for XR developers, robotics and Physical AI teams, and AEC and operations innovation leads. But it's also for the people the new capture economics just pulled in: the marketing, production, and cultural teams shipping their first splats this year. Practical first, technical second, and still entertaining for the theorists.
A 360 camera plus a disciplined twenty-minute walk now produces a photorealistic 3D scene of almost any space. What it does not produce, by default, is a scene that knows where it is, how big it is, or what's inside it. A visual positioning system (VPS) is the layer that adds those things: a shared coordinate frame, enforced metric scale, and a map that real devices can localize against in real time.
The rest of this post unpacks that table.
Reality capture grew up selling pictures. Its first paying customers wanted things to look at: property tours, design reviews, documentation walkthroughs. So the industry learned to treat the deliverable as the visual. Camera in, render out, done.
That framing is so embedded it survives even when the technology underneath changes completely. Meshes gave way to NeRFs, NeRFs gave way to splats, and the deliverable stayed the same: something pretty to fly through.
But a capture isn't a picture. It's a measurement. When you walk a building with a 360 camera, you're recording geometry, appearance, and, if you're disciplined about it, a coordinate frame. The splat isn't that dataset. It's one read-path of it: the projection optimized for human eyes. The same measurement can be read by machines, for localization, for navigation, for simulation. One capture, N projections.
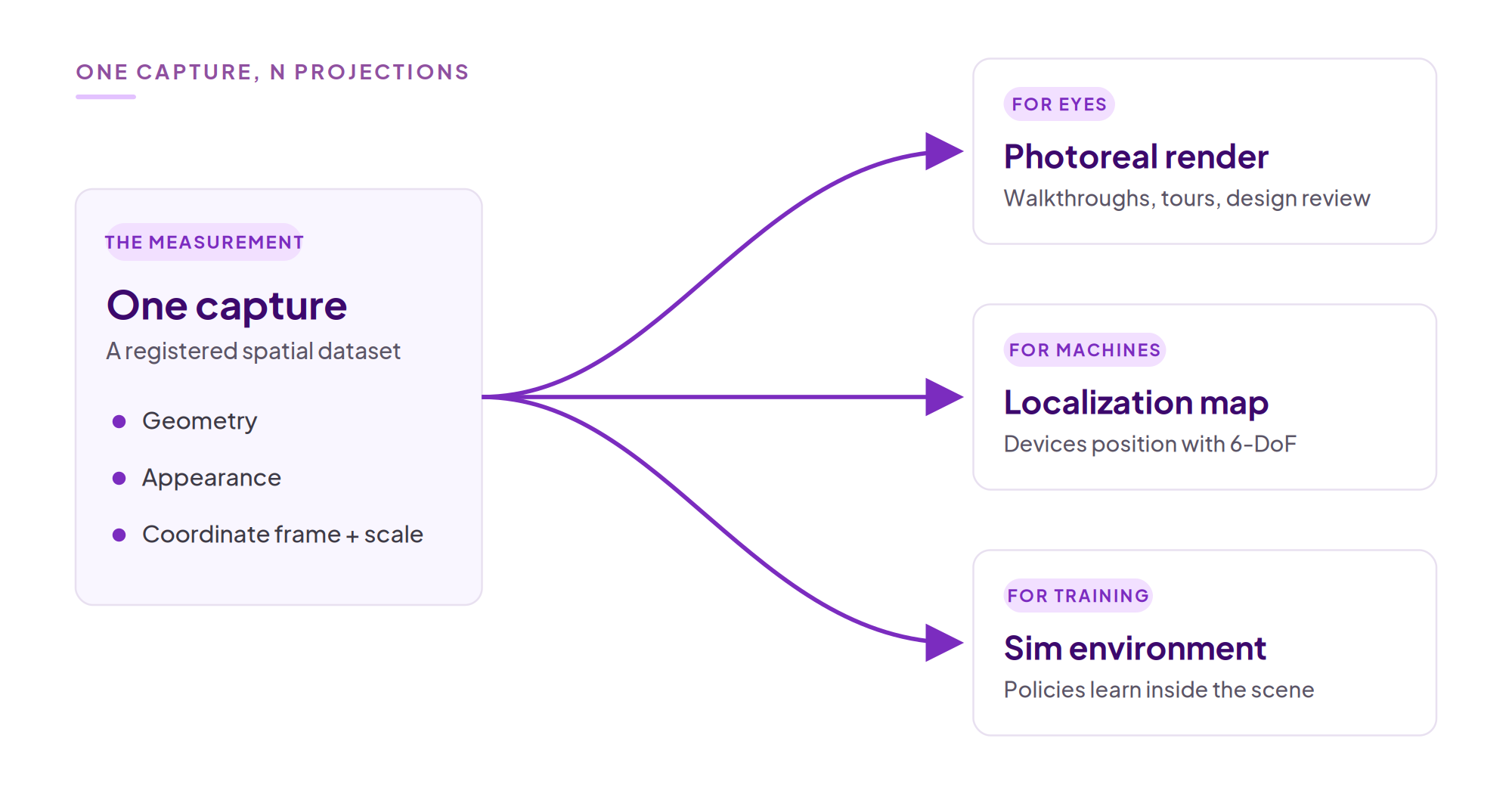
This matters because appearance fidelity and metric fidelity are different axes. A splat that's 7% wrong in scale looks identical to one that's exactly right. PSNR doesn't notice. Your eyes don't notice. A robot trying to dock at a charging station notices immediately. Eyes pay for pretty. Machines pay for true. And a pipeline that ships only the render leaves most of the measurement on the floor.
Before the critique, the credit, because the boom has earned it.
The standards arrived. In February, the Khronos Group released the KHR_gaussian_splatting extension for glTF 2.0 as a release candidate, with ratification targeted for mid-2026 and a companion SPZ compression extension behind it. OpenUSD ratified splat support in April. Splats are becoming the JPEG of 3D, and for once the cliché is structurally accurate: one file, any viewer, no plugin.
The platforms moved. At WWDC this month, Apple announced that Maps Flyover is being rebuilt on the same class of radiance-field representation, shipping this fall across more than 300 cities, likely the largest deployment of the technique to date. Esri now supports Gaussian splat layers in ArcGIS Enterprise 12.1 Scene Viewer, inside an organization's own infrastructure. Zillow's SkyTour turned drone footage into splat fly-arounds on home listings and proved that mainstream audiences will happily consume the format without being told what it is.
And the economics pulled in audiences that never owned a scanner. Hotel, venue, and vacation-rental marketers are shipping splats because a smartphone-accessible photoreal walkthrough sells a space better than a photo gallery, and nobody needs a headset. Film moved first on fidelity: Superman shipped roughly 40 shots built on the first feature-film use of 4D Gaussian splats, the Kryptonian-parent holograms captured by Framestore and Infinite Realities on a stage of roughly 192 cameras, while location scouting collapses from flying a crew to sending one person with a 360 camera. Retail teams are publishing shoppable splat showrooms and walking proposed store layouts before a single fixture moves. Cultural teams are preserving the unpreservable: during the Milano Cortina Winter Games this February, a two-week Olympic exhibition inside a Milan hospitality venue was reportedly captured as a navigable splat, outliving its own physical run. Game and interactive teams pull real locations straight into engines as level-design starting points.
Look at the last column. Every row has the same dependency: the moment a splat has to meet the building it depicts, looking isn't enough.
Here's the part the standards can't fix. Portability is not addressability. A ratified file format tells every viewer how to read your splat. It says nothing about where the scene is, how big it is, or how a device standing in the physical room could ever find itself inside the digital one.
The early web had exactly this shape. Millions of pages, each one viewable if you happened to hold its exact URL, collectively near-useless until indexes made them addressable. A standalone .ply is a page without a URL: a human can open it and fly around with a mouse, but a phone, headset, or robot standing in the very room it depicts cannot deduce its own position in it.
The causes are two, and they're geometric, not tooling gaps.
Scale ambiguity. Visual-only reconstruction is scale-ambiguous by what geometers call gauge freedom. The solver recovers relative distances perfectly. It has no mechanism to know whether your hallway is 5 centimeters long or 50 meters. Scale has to be injected from outside the images, and as we'll see, when you inject it matters enormously.
Coordinate isolation. Standard exporters place the origin wherever the first processed frame happened to be. Your scene floats in a private coordinate system, untethered from WGS84, from your facility grid, from every other splat you've ever made.
If you only remember one thing from this article, it's this: a splat you can see but cannot localize against is a dead asset. After the previous section, that should sting a little. If you're shipping splats today, your splat is worth more than you're using.
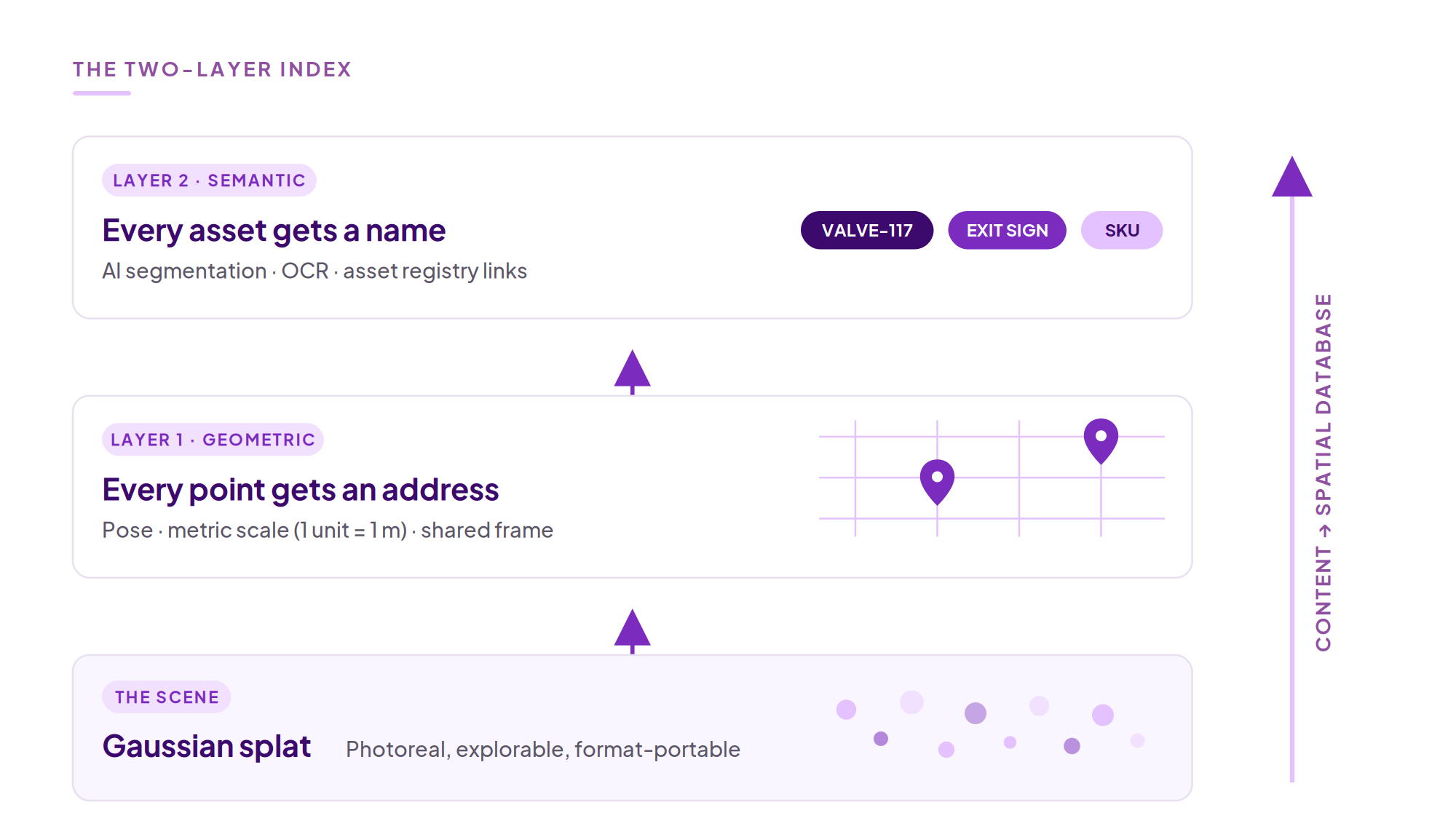
Indexing a splat means giving it two things, in order.
Layer one is geometric: every point gets an address. A shared coordinate frame, enforced 1-unit-equals-1-meter scale, and persisted camera trajectories. This is the layer that makes AR content stay where you anchored it, makes indoor wayfinding possible without beacons, aligns the splat to a BIM model or floor plan, and lets a robot treat the scene as a map rather than a screensaver.
Layer two is semantic: every asset gets a name. The same class of segmentation models that pipelines already use to mask the camera operator out of the footage is moving downstream, to segmenting and tagging the assets inside the indexed scene. Machines, cabinets, valves, extinguishers, exhibits, SKUs, identified in place. OCR reads labels, signs, and equipment identifiers straight off the environment. Address plus name turns a splat into a queryable spatial database. The retailer's showroom arrives auto-tagged with products. The museum's exhibits answer questions. The facility's assets link to the maintenance system that already knows their service history.
The research ceiling here is striking. GaussNav demonstrates agents navigating to a specific object instance by predicting what it should look like from angles never visited. LagMemo embeds language features directly into Gaussians, so an open-vocabulary query like "go to the red fire extinguisher near the main exit" resolves to exact 3D coordinates. POGS keeps object-level state as scenes change, tracking moved items through up to 12 consecutive resets and recovering from 80% of in-grasp perturbations. Feature-field work like GSFFs even localizes against abstracted features rather than raw imagery, which matters in facilities where raw camera frames can't leave the building.
And one observation worth sitting with: tagging is getting abundant. Segmentation models are commoditizing, OCR is solved, and enterprises hold asset registries waiting to be linked to physical locations. What stays scarce is addressability. A tag locked inside one viewer dies with that viewer. A tag pinned to a shared coordinate frame travels: across devices, across apps, across re-captures. The labels got cheap. The addresses did not.
Robotics gives the preview of where this goes. Policies trained inside splat environments already transfer to physical robots at an 86.25% zero-shot success rate in published work. Close the loop, train in the splat and deploy against the same map, and sim-to-real becomes sim-to-same-map. That deserves its own post, and it's coming.
Let's get technical without losing the plot.
What the map must contain. A splat alone is not enough to localize against. The engine needs the geometry and the camera trajectory that produced it: which views, from which poses, generated this scene. In practice that's the .ply plus a poses file recording a timestamp, a translation T, and a rotation quaternion R for every training frame (the exact schema is in the Gaussian splat ingestion docs). Without the trajectory, the geometric relationship between the splat and the physical space is mathematically unrecoverable. This is also why localization and reconstruction are secretly one problem: reconstruction solves poses plus structure from images, localization solves one new pose from structure. Same correspondence math, run in opposite directions.
Why scale must enter at capture time. Recall gauge freedom: images alone cannot determine absolute scale. The fix is to inject a known physical quantity at solve time, a printed ChArUco board of known dimensions in the scene, a calibrated stereo baseline, IMU data, or alignment to a floor plan. Injected during bundle adjustment, the constraint propagates through the entire solve, and the reconstruction comes out metric everywhere. Applied afterward, it's one global cosmetic correction that cannot repair scale drift across a large scene, and because each Gaussian stores its scale in log space, naive rescaling corrupts covariances until the splat visibly degrades. Pretty is decided in training. True is decided at capture.
No system is magic, and you should hear the failure modes from me rather than discover them in week two.
Feature-poor scenes. Blank corridors, repetitive racking, glass curtain walls. Spherical capture genuinely helps, because features persist across the full view sphere and loop closure improves, but coverage cannot invent texture that isn't there. Some spaces need deliberate treatment before they index well.
Changed environments. A map represents the space at capture time, and its validity decays at the rate the space changes. Warehouses re-rack, plants re-pipe, stores re-merchandise. The dangerous part is that a stale map doesn't fail loudly; it localizes confidently and wrongly.
Map lifecycle. Indexing is an operational discipline, not a one-time export. It means a re-capture cadence matched to your change rate, version control over maps, and validation after each refresh. Research like POGS and Scale-GS points toward maps that update themselves as objects move, and it's promising, but treat it as direction, not a production promise. The same honesty applies to the semantic layer: segmentation quality varies with clutter and category, tags inherit the staleness of the map beneath them, and upstream tags inherit upstream quality. The index places labels. It cannot correct them.
The right operational response is not denial. It's protocol and cadence, and a 20-minute re-capture makes cadence affordable in a way rig-based workflows never were.
Everything above is true regardless of vendor. Here's how we've built for it at MultiSet.
One pipeline, two outputs from the same capture: a human-readable, metric-scaled 3DGS and a machine-readable VPS map that devices localize against with full 6-DoF at a median accuracy around 5 cm. The pipeline is scan-agnostic on the way in: 360 video, existing splats, E57 point clouds, LiDAR. Registration survives format changes, which is the point. It runs in public cloud, private cloud, or self-hosted, and map versioning carries your anchors and tags forward across re-captures instead of resetting the world each time. Today that infrastructure spans 16M+ square feet mapped across 2,500+ locations in 116+ countries, with 500K+ device interactions against it. A Fortune 100 industrial customer runs this pattern in private cloud production.
[F5 IMAGE HERE: real product capture, device localizing inside a splat. NOT AI-generated.]
On the semantic layer, we're deliberately ecosystem-first. Treedis runs AI segmentation and OCR across entire facilities upstream, machines, cabinets, valves, signage, equipment identifiers, and brings those tags into MultiSet's spatial frame, already validated against MultiSet VPS. Native tagging is on our roadmap, but the architecture stands either way: your capture, your tags, your platform, our frame. We run as the substrate beneath partner tagging, not a competitor to it.
Days 1-2: protocol-first capture. One space. Locked exposure, low ISO, a planned walking pattern with deliberate loop closures, ChArUco boards placed before recording starts. Produce both outputs from the single capture and share the render internally the same day; it buys you goodwill while the real work begins.
Days 3-7: localization validation. Walk the space with a phone against the map. Tape-measure spot checks against in-splat measurements. Place anchors, leave, return tomorrow, confirm they held. Define acceptance per zone, not per building.
Days 8-14: production and cadence. Expand coverage, set a re-capture rhythm matched to how fast each area actually changes, wire map versions into your release process, and hand ops a runbook instead of a demo. Two weeks from first walk to production is the honest timeline, and it's the 20-minute capture that makes it possible.
Maybe you don't, yet. The day you will is the day the splat has to meet the building: a guest asking for directions inside the venue, a technician needing the valve highlighted on their screen, an exhibit that should respond when a visitor stands in front of it. You can't retrofit metric discipline into a casual capture, but you can capture once under discipline and keep the option open. The cost difference is a printed board and a better walking pattern.
Mostly no, and I'd rather be straight about it. Gauge freedom means the missing scale was never recorded, so the best you can do afterward is one global correction, which can't repair scale that drifts across the scene, and per-primitive log-space rescaling tends to corrupt the splat visually. Plan-alignment recovery exists and is sometimes good enough, with weaker guarantees. For spaces that matter, a 20-minute re-capture under protocol is usually cheaper than rescuing the archive.
No, it's aging, and the decay is zonal rather than total. Loading docks change weekly; lobbies change yearly. Versioning plus partial re-capture handles this: refresh the zones that moved, keep the ones that didn't, and let anchors and tags carry forward. The operational question isn't whether to re-capture but at what cadence per zone.
Formats will keep cycling. Point clouds, meshes, NeRFs, splats, whatever 4DGS matures into next. The conserved quantity across all of them is the registration: the poses, the scale, the shared frame. Bet on a format and you're renting. Bet on the registration and you own an asset every future format can be regenerated from.
The lock-in fight of the next decade isn't headsets. It's spatial data. And an unindexed splat is data without an address.
If you'd like to give yours one: start free on the developer portal or book a demo. Twenty minutes of walking is all the hardware asks.
Further reading: 360 Video to VPS · 3DGS to VPS · E57 to VPS · Map Versioning · Gaussian Splat Ingestion Docs · Visual Positioning System Overview



